
Steps you can take to mitigate the threat—the data behind the findings.
Amazon Simple Storage Service (Amazon S3) is, in Amazon’s words¹, “an object storage service offering industry-leading scalability, data availability, security, and performance.” Amazon S3 is by far the largest data storage software with 44.66% of market share². Customers of all sizes and industries can store and protect any amount of data for virtually any use case, such as data lakes, cloud-native applications, and mobile apps. Organizations use S3 buckets for the flexibility they offer developers and data scientists to quickly and easily store, access, and share almost any file or object from anywhere, at the click of a button. No cumbersome implementation process required.
We think of any data that an organization wants to keep confidential including things like highly regulated data like PHI, PII or PCI data, customer and employee information, and trade secrets as sensitive data.
The U.S. Department of Labor defines personally identifiable information (PII) as “any representation of information that permits the identity of an individual to whom the information applies to be reasonably inferred by either direct or indirect means.”
Within a bucket every item within that bucket is an object. For the purposes of this post, every object in a bucket is a file and the two words can be used interchangeably.
“To know what you know and what you do not know, that is true knowledge.”
– Confucius
We started this project because we wanted to know what kind of data we could find in publicly exposed S3 buckets, so that we could understand the potential exposure, and advise on how best to mitigate. To achieve this we got a sample of publicly exposed S3 buckets, and because nobody except possibly Skynet³ has the ability to review all publicly exposed S3 buckets, we determined that 308,441,001 files in 85,214 buckets was a solidly representative sample size.
How can my file be public?
To understand how data becomes inadvertently publicly exposed, and why it may happen, we first have to understand how the access is enabled. By default new buckets, access points and objects don’t allow public access. However, there will be times that users will want to have a file publicly accessible (for example – images and files used by websites).
There are two main ways a file in an S3 bucket can be made public*.
Allowing the entire bucket to be accessed from the internet – Amazon allows you to set a policy that enables all files in the bucket to be publicly accessed. This is called a “bucket policy”.
Allow only specific files to be accessible from the internet
This second option means that even if the bucket is not public, a file inside it can still be accessed from the internet if the ACL grants the relevant permissions.
* For these to work, you can’t have any block public access settings at the account level or the bucket level. By default, block public access settings are set to True on new S3 buckets. If the block public access feature is activated for all buckets within the account, the message “Bucket and objects not public” is shown and an S3 bucket may not be made public by users until the block is lifted by the administrator.
Important: Granting public access through bucket and object ACLs doesn’t work for buckets that have S3 Object Ownership set to Bucket Owner Enforced. In most cases, ACLs aren’t required to grant permissions to objects and buckets. Instead, you can use AWS Identity Access and Management (IAM) policies and S3 bucket policies to grant permissions to objects and buckets.
Note: As of April 2023, all new S3 buckets will have ACLs disabled and S3 Block Public Access settings enabled for all new buckets4.
Once data is publicly accessible it’s easy to obtain. There are many websites that enable you to search for publicly accessible documents in S3 buckets. Any person in the world, including, of course, attackers, can access and then mine this data – from phone numbers, addresses, and credit card details to internal proprietary information and private medical information. Armed with this information, attackers can then do a number of things with long-standing impacts on the organization to which the data belongs—from mis-use of proprietary information to gain an unfair competitive advantage to credit card fraud to ransoming of customer data. And, of course, organizations also have to worry about potential compliance violations due to misuse of regulated data like PHI, PII or credit card information.
Examples of real-world impacts
Organizations across industries, regions, and sizes should beware of the risk of sensitive data being made inadvertently or unintentionally publicly accessible. To put it into real-world context, here are just a few examples of organizations who’ve seen the impacts from data in publicly exposed buckets, and, unfortunately, the subsequent press coverage.
The list could go on, and on, but we’ll stop here so we can move on to the data. Oh yes, it’s always all about the data.
As mentioned, we used a sample size of 85,000+ publicly accessible buckets and the files within. Then we used our unique classification software to determine how much of this data was sensitive data. Based on this we concluded that a full 21% of these representative buckets contained sensitive data. We found everything from internal company performance reviews, complaints filed by employees, welfare payment details, private medical information, financial information to the more standard but still concerning username, zip code and email address.
Now let’s walk through how we got to the data that we found the most troubling. First, we took all of the file data and looked at which files had the most unique data types in them. Unique in this case means those files with a lot of data like emails, phone numbers, names, addresses and social security numbers. Then we examined the buckets with the most files containing that type of PII. Within those buckets we narrowed our focus to the ones that also contained publicly accessible PDF or Word documents, given that having such documents usually points to the fact that these files should not be public. Finally, from the set of these buckets with a large amount of files with PII and PDF or Word documents we selected those that had the most unique data types.
Because we had to obfuscate to protect the anonymity of the innocent, what you’re looking at are: Files containing PII of people who used a third-party chatbot service on different websites – including names, phone numbers, emails – and the messages sent to the bot (for example – people seeking welfare benefits); files containing loan details – name, loan amount, credit score, interest rates and more; a participant report for an athletic competition, including PII (name, address, zip code, email and more) and medical info; a VIP invite list including names, email, and address information; file with first names, last names, ethereum address and bitcoin address information, and block card email addresses.
Now that we had discovered that there was indeed a lot of sensitive data publicly exposed, and some of it, as listed above, incredibly concerning, we wanted to understand where the exposure was happening.
Misadventures in misplaced data
As expected, quite a few of these files are public due to a simple mistake made by the person configuring the bucket’s access policy or the person unintentionally adding private, sensitive data to a publicly accessible bucket. Most of the most concerning data we found was due to the latter, the advent of “misplaced” data. Things that lead us to believe that these files were exposed due to mistakes in general:
We believe most of the sensitive data we found is misplaced and not misconfigured because we found buckets with data types that should be in a publicly accessible bucket, but one file that didn’t belong and had sensitive data. The clear implication from that is that this file was misplaced in this bucket intended to be public.
The more worrying pattern we found during this research was the amount of data leaked by third party software companies. Given the most highly concerning sensitive data we found centered around the type of data that by its nature clearly was shared via third party software company, it seems that companies offering services such as HR management software, providers of live chat software, online event registration software companies and more are the biggest, or at least most concerning, source of exposed sensitive PII. Given this, it is clearly not enough anymore to make sure that your company’s data is safe, but also that the third parties who can access your data comply with data safety regulations and that your organization is submitting them to a fairly rigorous security review before sharing data with periodic audits.
Now that we’ve scared you with the kind of data we’ve found in publicly accessible buckets, here are a few things you can check to see if your files are publicly accessible and then change access settings as needed:
You can see if your bucket is publicly accessible in the Buckets list. In the Access column, Amazon S3 labels the permissions for a bucket as follows:

You can also filter bucket searches by access type. Choose an access type from the drop-down list that is next to the Search for buckets bar.
If you want to change public access for a single object (file) (this is also the only way to see if a file is publicly accessible):
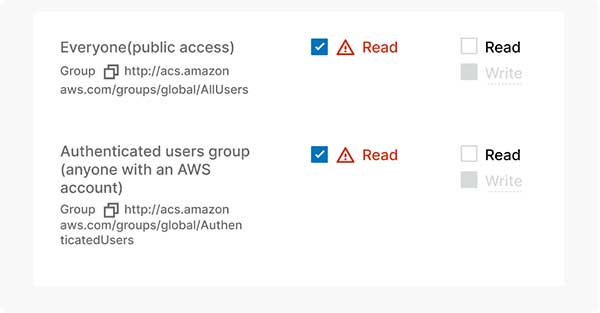
If any of your buckets or objects are publicly accessible, the best practice for protecting data at scale is to use a DSPM solution. We don’t want to get overly promotional in our research posts, so we’ll leave it at that.
With the stakes as high as they are and attackers always on the lookout for ways they can gain a financial edge, it’s vital to keep control over sensitive data. As we’ve uncovered, this includes ensuring that your data is not part of the 21% of sensitive PII unintentionally publicly exposed.
Fortunately, there are steps you can take to mitigate the threat of exposure,and we hope that this post helps, but constant vigilance is required.

Industry in Transition: The Forces Reshaping Manufacturing
As manufacturers offer more customization than ever before, managing product complexity has become a critical challenge. Tune in with Dan Joe Barry, Vice President of Product Marketing at Configit, who explores how companies are tackling the growing number of product configurations across engineering, sales, manufacturing, and service. He explains how Configuration Lifecycle Management (CLM) helps organizations maintain a single source of truth for configuration data. The result: fewer errors, faster quoting, and the ability to deliver customized products at scale.
Get In Touch
Google news and SEO compliant, Industry Today’s state-of-the-art digital media platform offers bespoke media campaigns that target key decision makers and buyers to achieve your marketing and promotional goals.
![]()
Contribute
Showcase your brand and promote your business to our highly targeted audience. We offer detailed Google Analytics with measurable ROI to assure success. Submit your content for review by our Editorial team who will contact you to discuss the project further.
About Us
Reach Your Targeted Audience and Grow Your Business. Learn more About Industry Today.
Contact Us

© 2026 Industry today. All Rights reserved.














