
Applying AI and ML to simulation-driven design delivers results and product efficiency in shorter timeframes without sacrificing accuracy.
By Dr. Mamdouh Refaat, Chief Data Scientist, Altair
The last three decades have experienced rapid growth in the use of simulation tools in product design. Integrated with computer aided design (CAD) tools, simulation software is now a fundamental ingredient in the practice of computer aided engineering (CAE). During this journey, the finite element method (FEM) emerged as the main tool for simulation in many areas of product design such as structural integrity, computational fluid dynamics (CFD), electromagnetic analysis, and structural topology optimization. Because of the success of FEM addressing many design challenges, the complexity of the problems presented in FE simulation has grown rapidly.
FEM has become the top physics-based simulation technique and the number of elements involved in a FE simulation have increased by a factor of ten every decade. The typical design problems that were being simulated in the 1990s used a few thousand elements and these problems are now solved using several million elements. This allows a more authentic representation of real-life problems. As a result of the increased problem size, the computing resources needed for FE simulation has grown dramatically and represent a non-trivial cost element in the design process.
While the FE simulation world was integrating and solving a wide range of problems, jobs started to become larger and larger. At the same time, artificial intelligence (AI) and machine learning (ML) has been advancing and inventing new methods that address the complexity of the same design problems. Recent advances in deep learning and the implementation of these methods using specially designed platforms running on GPU-based clusters are allowing ML models to shortcut the simulation process by summarizing the results of simulations. In doing so, the ML model serves as a repository of the wisdom gained from multiple simulation runs. The clear benefit of using ML is the reduction of number of simulation runs during the design of a new, but similar, product.
ML models have been applied on a large scale in other industries and most notably, the credit industry. In fact, ML models have been in production in the financial credit industry for more than three decades. The only difference is that they were not labeled as ML models, they were called “credit scoring” models. The most common format of these models is the “standard credit scorecard” [1]. Scorecards are ML models that are fitted (or trained) on historical data of customers who were awarded some form of credit, such as a credit card or loan. The training data, which contains the default behavior of the customers, is typically extracted from application and transaction history of these customers. The scorecard models are fitted to predict the default behavior of the customers in terms of some variables representing the characteristics of customers and their transaction patterns. These models are then used to score new applicants to determine their credit worthiness.
The same process is currently being applied to the simulation-based product design process. In this case, the physics-based simulation generates the data that describes the behavior of the different product designs under operating conditions (loading of different forms including mechanical, electromagnetic, fluid flow, and more). This data is then used to train ML models to capture the behavior of the different product designs under loading conditions. For example, one could simulate the crash behavior of a car door with different designs and loading configurations and generate data that represents the crash worthiness of different door designs with materials. Then a ML model is fit on this data, to capture this crash behavior. When testing a new design the design is scored using the ML model rather than starting with FE simulation. The ML model scores may reveal that the proposed design does not meet the design criteria. Before conducting a time consuming and expensive simulation, ML models are used to validate the proposed design.
The above methodology is being used by several clients of Altair and is showing a dramatic reduction in the needed number of physics-based simulation runs reaching 90 percent in some cases.
ML models have been around for more than 60 years since the publication of the first neural network paper by Rosenblatt in 1957 [2]. Until about 20 years ago, the use of ML models was limited to specific applications in business, mainly credit risk scoring or marketing. With the recent development of industrial strength open source implementations, with some of them backed up by large commercial organizations, it has become easy to apply ML models to other areas including product design. These new libraries not only were free to use and implement in proprietary projects, but were also extended to run on large clusters of GPU’s. This allowed the modeling of more complex and challenging problems that required more computing power and more complex ML models. The modeling technique responsible for most of these developments is known as “deep learning” which is incidentally an extension of the original Rosenblatt paper from 1957.
Deep learning is an ambiguous term used to denote a collection of models mainly implementing neural networks with many layers to challenging classification and estimation problems. The rapid growth of the power of deep learning techniques can be attributed to the development of parallelized versions of the deep learning models that can be run on GPU-based computer clusters. This allows them to tackle problems of high complexity and simultaneously achieve high accuracy by being able to use large complex training datasets efficiently. This boosted the applicability of deep learning models to the difficult problem of representing the simulation results of FE analysis used in product design on an industrial scale for real complex problems.
Figure 1 summarizes how ML works with simulation data. We start with a set proposed designs for the product in mind. We describe these designs in terms of some parameters or variables that represent the geometry, material, and the loadings of each design. The number of these designs should be sufficiently large to cover the range of possible designs we expect to have. We then perform physics-based simulation on these designs and calculate the targeted performance criteria. In the case shown in Figure 1, we use some failure criterion to determine whether the product would sustain the applied operational loads.
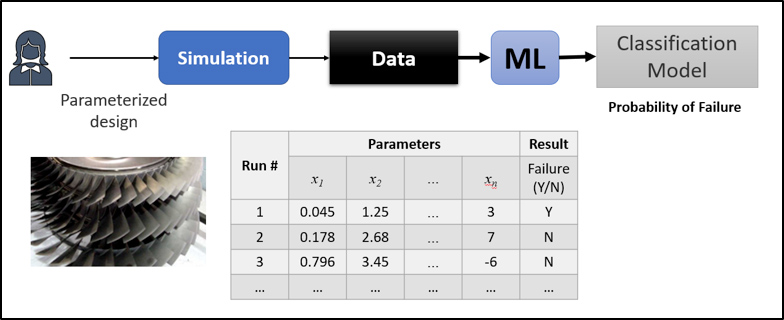
Figure 1: Data extraction from simulation results and training of ML model
The data from different simulation runs are then organized in a dataset as shown in Figure 1. This data is used to train (or simply fit) a ML model. In this case, because the output of the ML model is a binary outcome (failure: Y/N), the ML model will be fitted to predict the probability of failure. The inputs to this model are the various variables that can be used to characterize the product design in each FE simulation run. These variables characterize the design geometry, material properties, loading conditions, and any special feature that differentiates between the different designs. We will denote these variables as x1 – xn in Figure 1. When there is a new proposed design of the product, we will characterize that design with these variables. The data set that contains the parameters x1 – xn as well as the output of the simulation in each case is known as the training data. This is the dataset that will be used to train the ML model.
There is a large variety of ML algorithms that could be used to fit such training data for different purposes. These algorithms vary according to the nature of the task at hand. The task in the example of Figure 1 is a classification task. This means that we aim at finding a model (an equation, or rule) that will classify new designs using some failure criteria by predicting the likelihood (probability) of failure. One of the most powerful family of such algorithms for training ML models is deep learning. This has been successfully applied to the problem of part design from results of physics-based simulation. There are several powerful open source libraries as well as commercial softwares that offer a variety of ML algorithms, including deep learning, that can be used in ML models for product design as described above [5],[6],[7].
After training the model, it can be used to calculate the likelihood of failure of products of similar designs within the same range of characteristics as those used in the simulation runs. This second phase of using ML is depicted in Figure 2 below.
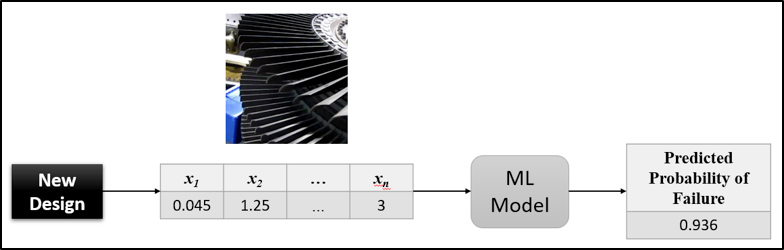
Figure 2: Scoring new designs using the trained ML learning model
When encountering one or more newly proposed designs of the product to evaluate, it is not done by running FE simulations, but by scoring these designs using the trained machine learning model. With this, the values of the characteristics x1 – xn are extracted for the new designs and are used as inputs for the trained ML model. This model will predict the probability of failure for each of these designs. This scoring process is depicted in Figure 2. The process of scoring ML models is very fast and computationally inexpensive compared to FE simulations. Typically scoring a ML model of real complex products is expected to take a few seconds or less.
One of the important factors in the success of FEM as the prime physics-bases simulation tool, is high accuracy. Any candidate approach that would be introduced to the world of simulation will have to produce comparable accuracy to that offered by the FEM.
It has been demonstrated that ML-based models can produce accurate results as those obtained by physics-based simulation. For example, [3] the accuracy of using ML modeling to reproduce the FE results representing the mechanical behavior of the human heart [4] showed how ML can act as an accurate surrogate to FEM to calculate stress distribution.
Using ML models to shorten the simulation cycle has been successful in the design cycle of many products. Although we expect to see a rapid growth in the application of this methodology in the next few years, there are some challenges that need to be addressed before ML becomes a standard tool for the design engineer.
The first challenge is the current engineering design practice. Most engineers create a set of designs and use FE simulation to test whether these designs meet the acceptance criteria. When a design fails and proves to be sub-optimal, the data from simulation run is deleted as a failed attempt. In order to train ML models, the simulation data of these failed designs is needed. Engineers will need to update their data management practices and create a repository of simulation runs, both good and failed designs, in order to use this data in ML models.
The second challenge is to effectively use a data repository for the simulation data. Engineering design groups will need to invest in data management platform in order to organize, clean, and make data available from simulation runs. This platform is different from the current product lifetime cycle software. The focus of the new platform is the organization of the data for the purpose of developing ML models. The challenge is not a technical one, but the fact that engineering design departments will have to adopt a data driven approach to design, rather than a simulation driven approach. The FE simulation changes from being a tool in the design cycle to a tool of data generation. Transforming from a platform of managing data, to a platform in which the product design lives and functions.
The third challenge is the need to train design engineers in the art of data science to enable them to implement best practices in ML. Although it is expected that many steps in the ML model developing process will be automated over the next few years (auto-ML), the design engineer still needs to have some fundamental knowledge about ML models and how to properly implement them. It is expected that most of the FE simulation vendors and engineering departments in universities will launch their own ML training courses for design engineers to fill this skill gap.
The last challenge is the influence of Internet of Things (IoT) and digital twin on product design and the overlap with ML. Current practices in product design are already taking advances in IoT and digital twin to adapt designs to the new world of connected products. Sensors generating data about the product performance during operation will also need to be integrated in the new data management platform to be used in training ML models for the design of new products, and the performance optimization of existing products in operations. In fact, the advances in IoT and digital twin are removing the boundaries between the data available at design time and what is available during operating the product. The boundaries are becoming fuzzy, and that in fact adds another opportunity for ML to use operational data to further tune the ML models.
In numerical analysis courses it is taught that numerical problems could be solved quickly using a limited number of iterations, but in most cases it would lead to lower accuracy. In order to achieve higher accuracy, more iterations or higher order terms would need to be used to result in more complex computations that need more resources.
Today with the recent advances in ML, an exception to the above rule above has been found. FE simulation allows the modeling of the most complex structures, while ML can help optimize the use of simulation resources to make product designs more efficient without sacrificing accuracy.

Dr. Mamdouh Refaat
Dr. Mamdouh Refaat
Chief Data Scientist
Altair
Mamdouh is Altair’s chief data scientist and senior vice president, product management where he is responsible for the company’s data analytics products. Refaat is an expert and published author with more than 20 years of experience in predictive analytics and data mining, having led numerous projects in the areas of marketing, CRM and credit risk for Fortune 500 companies in North America and Europe.
Refaat joined Altair (then Angoss) in 1999 to establish the company’s consulting practice before assuming leadership for data science. Prior to joining Altair through the acquisition of Datawatch, he held positions at Predict AG (acquired by TIBCO Software) and UBS in Basel, Switzerland.
Refaat earned a PhD in Engineering from the University of Toronto and an master of business administration degree from the University of Leeds.
Mamdouh’s notable publications include the books, “Data Preparation for data mining Using SAS, 2006,” and “Credit Risk Scorecards: development and implementation using SAS, 2011.”
References
[1] “Credit Risk Scorecards: design and implementation using SAS”, Mamdouh Refaat, Elsevier, NY, 2011.
[2] “The Perceptron — a perceiving and recognizing automaton”, F. Rosenblatt, Report 85–460–1, Cornell Aeronautical Laboratory, 1957.
[3] “Prediction of Left Ventricular Mechanics Using Machine Learning”, Yaghoub Dabiri, Alex Velden, Kevin Sack, Jenny Choy, Ghassan Kassab, and Julius Guccione, Frontiers in Physics. Vol 7. (2019).
[4] “A deep learning approach to estimate stress distribution: a fast and accurate surrogate of finite-element analysis”, Liang Liang, Minliang Liu, Caitlin Martin, and Wei Sun, Journal of The Royal Society Interface, Volume 15, Issue 138.
[5] “Machine Learning Library in Python – Scikit Learn”, https://scikit-learn.org.
[6] “Keras: The Python deep learning library”, https://keras.io/.
[7] Altair Data Science and Machine Learning, https://www.altair.com/machine-learning/.

Forging the Next 250 Years: Powering the Next Era of American Manufacturing
As manufacturers offer more customization than ever before, managing product complexity has become a critical challenge. Tune in with Dan Joe Barry, Vice President of Product Marketing at Configit, who explores how companies are tackling the growing number of product configurations across engineering, sales, manufacturing, and service. He explains how Configuration Lifecycle Management (CLM) helps organizations maintain a single source of truth for configuration data. The result: fewer errors, faster quoting, and the ability to deliver customized products at scale.
Get In Touch
Google news and SEO compliant, Industry Today’s state-of-the-art digital media platform offers bespoke media campaigns that target key decision makers and buyers to achieve your marketing and promotional goals.
![]()
Contribute
Showcase your brand and promote your business to our highly targeted audience. We offer detailed Google Analytics with measurable ROI to assure success. Submit your content for review by our Editorial team who will contact you to discuss the project further.
About Us
Reach Your Targeted Audience and Grow Your Business. Learn more About Industry Today.
Contact Us

© 2026 Industry today. All Rights reserved.













