
Production stoppages like the Jaguar Land Rover one are inevitable; resuming production safely is what makes manufacturers resilient.
By Craig Mackay, CPO, Macrium
When Jaguar Land Rover took systems offline following a security incident, the immediate headlines focused on cyber risk. But for manufacturers watching closely, the main concern wasn’t that a potential cyber incident had led to a halt in production, but how long it took to get production moving again. At one stage, UK car production fell to its lowest point since 1952, sending shockwaves through the industry as everybody along the chain, from suppliers to retailers, felt the sting. Questions were being asked about a potential cyber incident and what the nature of it might be, but incidents like this are rarely about one point of failure. Even if a cyber incident derails production, the inability to get things back up and running swiftly often points to issues far deeper beneath the surface. Decades of accumulated technology often mean that the path back to productivity is slow, fragmented, and laden with recovery and compatibility issues.
Walk around any factory floor and you’ll see equipment, tooling, and operational technology (OT) that is decades old. Operating systems are retained because replacing them would mean replacing certified machinery. Embedded builds are tied to specific chipsets. Industrial PCs rely on exact driver combinations and firmware versions that can’t be simply “swapped out”. Over time, these environments evolve and new components are added, and those small changes accumulate. Firmware updates are applied, replacement components are installed that vary slightly from their predecessors, and configuration drift begins to creep in.
So, when disruption hits, as it inevitably will do at some point, recovery is about more than simply restoring a backup image. A precise operational state must be recreated in a hardware environment that may no longer be identical to what existed when the backup was taken, and that can lead to countless errors and incompatibilities that extend downtime and complicate the process of getting things back online.
While a dashboard may show a successful backup job, in OT these digital signals and green flags alone do not actually confirm that a restored system will boot correctly long term. In the UK alone, a recent Censuswide survey revealed that manufacturers collectively lose up to £736 million each week due to downtime. In the US, nearly half of manufacturers report 6-10 incidents per week, costing upwards of $207 million. The point is that the cost of disruption is not just the incident itself, but the time required to return to full operational capacity.
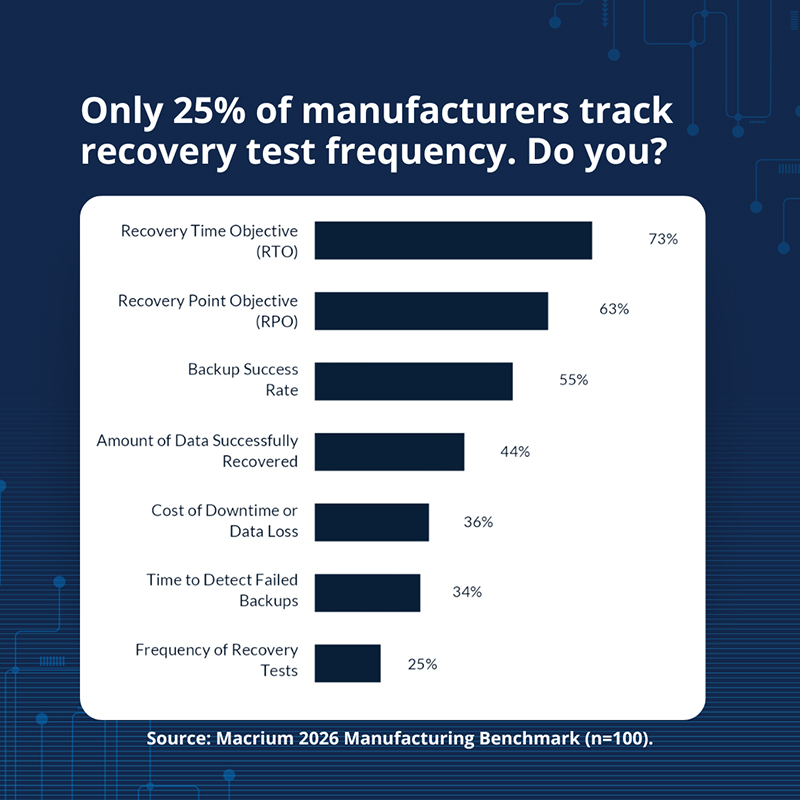
A lot of organizations rightly track recovery time objectives (RTO) and recovery point objectives (RPO). Those metrics are important, because they provide a target for how quickly systems should be restored and how much data loss is acceptable. But tracking objectives doesn’t confirm that recovery will work when the time comes. According to Macrium’s 2026 benchmark report, 73% of manufacturers track RTO and 63% track RPO, but only 25% track how often their recovery capabilities are tested. In simple terms, this means organizations often measure preparedness more frequently than they verify it. Saying you’re prepared and being prepared are two entirely different things.
And in an industrial setting, this gap between perceived readiness and actual readiness can be significant. A restore that works in a virtual test environment may still fail when deployed to the physical hardware that controls a production line. Differences in drivers, firmware versions, or peripheral interfaces can introduce failure points that only appear under real-world conditions. Here, resilience depends on reducing unknowns before an incident occurs, which requires moving beyond the assumption that a completed backup equals a recoverable system.
The short answer to the questions posed above is that industry leaders and IT/OT teams need to think about validation, not just verification, of their backups.
Integrity checks help identify silent backup corruption early, while scheduled test restores confirm that systems can boot and operations can initialize as expected. All the while, periodic validation should involve representative hardware rather than just virtual machines, because production environments are rarely generic, and recovery plans should reflect that reality. What works in one facility may not necessarily work in another, even if those facilities are owned and operated by the same company.
This is where validation becomes a routine discipline rather than merely a box-checking exercise or a question of compliance. Like any other form of due diligence, outcomes need to be documented, procedures need to be refined, and tabletop recovery exercises need to be built into regular operations as environments change and evolve over time. That way, recovery becomes predictable rather than improvised, and instead of relying on reassurance from a dashboard, teams build evidence that restoration will work under pressure.
For years, resilience discussions in manufacturing have centered on prevention, with network segmentation, threat detection, and faster response times all playing an essential role. But in the interconnected webs on which industry 4.0 operates, no defensive posture can be perfect. Incidents will occur, and disruption will follow. The organizations that are able to recover effectively while suffering minimal losses all share a common trait – they rehearse, simulate, measure, and document. The difference between a temporary interruption and a prolonged shutdown often lies in preparation that happened months earlier. Incidents may be inevitable, but costly periods of extended downtime aren’t.

About the Author:
Craig Mackay is Chief Product Officer at Macrium where he leads product strategy, innovation, and go-to-market execution. With nearly four years at Macrium, first as Head of Product and now as CPO, Craig has been instrumental in establishing the product function from the ground up, transitioning the business from perpetual licensing to a subscription model, and overseeing the launch of major product versions. Before Macrium, he spent over eight years at Emirates Group, where he held senior product and ecommerce leadership roles.

Forging the Next 250 Years: Powering the Next Era of American Manufacturing
As manufacturers offer more customization than ever before, managing product complexity has become a critical challenge. Tune in with Dan Joe Barry, Vice President of Product Marketing at Configit, who explores how companies are tackling the growing number of product configurations across engineering, sales, manufacturing, and service. He explains how Configuration Lifecycle Management (CLM) helps organizations maintain a single source of truth for configuration data. The result: fewer errors, faster quoting, and the ability to deliver customized products at scale.
Get In Touch
Google news and SEO compliant, Industry Today’s state-of-the-art digital media platform offers bespoke media campaigns that target key decision makers and buyers to achieve your marketing and promotional goals.
![]()
Contribute
Showcase your brand and promote your business to our highly targeted audience. We offer detailed Google Analytics with measurable ROI to assure success. Submit your content for review by our Editorial team who will contact you to discuss the project further.
About Us
Reach Your Targeted Audience and Grow Your Business. Learn more About Industry Today.
Contact Us

© 2026 Industry today. All Rights reserved.













